Ich habe bisher fast alles mit Python lösen können. Dennoch konnte gerade beim Arbeiten mit Objekten, die viele Elemente beherbergen (z.B. der iExam-Fragenpool) eine hohe Performance nur mit Tricks wie multi-threading und subprocessing zum Verteilen auf die verschiedenen Prozessoren erreicht werden und selbst dann hatte ich immer den Eindruck, dass die Serialisierung mit cPickle etwas bremste.
node.js hat mich in ersten Tests mit erstaunlicher Performanz überrascht und ich habe mich gefragt, wie es sich im Umgang mit Objekten im direkten Vergleich schlagen wird.
Erst einmal mussten ein paar Zeilen Code her, um die beiden Kontrahenten fair vergleichen zu können.
#! /usr/bin/python
# python code
# start with >> python2.7 testFileIO.py
import os, sys
import random
import cPickle
import time
datapth = '/Users/usrName/Desktop/nodeWork/Testdaten'
outpth = '/Users/usrName/Desktop/nodeWork/testErgPy'
# prepare & save Testdaten
with file(datapth,'wb') as outFle:
print >> outFle, ''.join( map(chr, [random.randint(0,255) for i in xrange(150)]) )
ergs = dict()
for i in xrange(10000):
ergs['%05i'%i] = '000000'
# Zeitmessung starten
sTM = int(time.time()*1000)
ssTM = sTM
for i in xrange(10000):
r = file(datapth)
erg = r.read()
tm = int(time.time()*1000)
ergs['%05i'%i] = tm-sTM
with file(outpth,'wb') as ofle:
cPickle.dump(ergs,ofle)
ergs = cPickle.load(file(outpth))
sTM = tm
print 'python needed: %s ms'%(tm-ssTM)
Durch die Vorbelegung der Dictionary-Elemente bleibt der IO-Aufwand über die Aufgabe weitgehend gleich. Da die tatsächliche Zeitdifferenz im ergs-Objekt abgelegt ist, kann das auch grafisch belegt werden.
Wie man sieht, beherbergt der Pythoncode keine Tricks (s.o) – um den direkten Vergleich mit Node.js zu erreichen, das ja bekanntlich in einer Schleife auf einem Prozessor läuft.
Unten steht die selbe Routine in coffeescript. Die intFormat(zahl, zeros) erzeugt eine Anmutung der Integerdarstellung im Formatstring bei Python ‚%05i’%i
#! /usr/local/bin/coffee
# coffeescript code auf node.js v0.6.7
# start with >> coffee testFileIO.coffee
fs = require 'fs'
cntr = 0
fle = ''
datapth = '/Users/usrName/Desktop/nodeWork/Testdaten'
outpath = "/Users/usrName/Desktop/nodeWork/testErg"
ergs = {}
intFormat = (zahl,zeros) ->
zahl = ''+zahl
prefx = ''
len = zahl.length
for i in [0...(zeros-len)]
prefx += "0"
prefx+zahl
for i in [0...10000]
ergs[intFormat(i,5)] = '000000'
# Zeitmessung starten
altTM = new Date()
altTM = altTM.getTime()
ssTM = altTM
for i in [0...10000]
erg = fs.readFileSync datapth,encoding='utf-8'
tm = new Date()
tm = tm.getTime()
ergs[intFormat(i,5)] = tm - altTM
fs.writeFileSync outpath,JSON.stringify(ergs)
altTM = tm
console.log "node.js time gone: #{ tm-ssTM } ms"
Die Aufgabe für beide bestand also darin, in einer Schleife zehntausendmal ein dictionary Object mit 10.000 Einheiten aus einem File zu laden, ein Element zu ändern (float hineinschreiben), das dictionary zu serialisieren und wieder abzulegen.
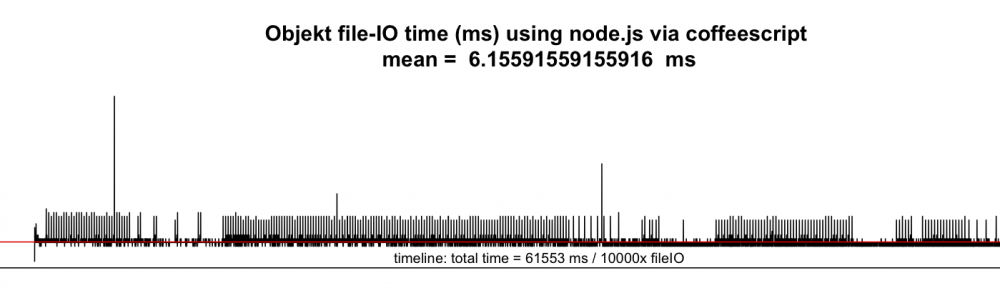
Und hier ist das Ergebnis (gemittelt aus 10 Durchläufen):

Das File, das Python bei der Serialisierung mit cPickle anlegt (39.000 Zeichen/ 319kb), ist 3x größer als die JSON-Datei, die Node erzeugt (20.000 Zeichen/ 100kb). Das kann die unterschiedliche Performanz zum Teil erklären. Aber die Aufgabe war ja gerade, ein großes Objekt frequent zu laden und zu manipulieren – genau hier zeigte sich die V8javacript engine von node.js deutlich im Vorteil.
Fazit:
Node.js war im Mittel praktisch 5.37 mal schneller als Python (MacPro 3,1 Xeon (8x, 2.8 GHz)).
update on MacBook Pro (2.26 GHz Core2Duo): node.js 5.06 mal schneller als Python 2.7.2